Web scrapers could be called the unsung heroes of data liberation. They invisibly power so many websites including real estate search sites, product comparison sites and the ever familiar Google search engine.
Scraping is where you run a program to extract structured data from web pages.
Web scraping powers PlanningAlerts, which allows you to find out what’s being built and knocked down in your area. It works by running lots of scrapers to collect the development applications from nearly one hundred planning authority websites.
In fact our other projects OpenAustralia, ElectionLeaflets and RightToKnow depend in one way or another on scrapers too.
For some while we’ve been using a scraping platform, ScraperWiki Classic, to host most of our scrapers. The system took care of running them regularly and giving PlanningAlerts a nice API with which we can get the data.
Scrapers are a little different than other kinds of code. They are dependent on the page layout of a web page remaining consistent. If a website that is being scraped changes then the scraper needs adjusting. To make it easy to maintain scrapers we need an easy way to find out when things need adjusting and we need easy tools for multiple people to help fix things.
ScraperWiki would send us email alerts if any of our scrapers would break. It’s a tool that really served us well.
Unfortunately for the OpenAustralia Foundation, late last year ScraperWiki announced that they would be shutting down their ScraperWiki Classic service. For a while now most of their effort has gone into developing their new platform, which has gone hand in hand with a refocusing of the company’s efforts away from providing free services and towards its paid data science work. This is completely understandable but left me wondering what to do next.
This is what I wrote to Francis Irving, the CEO of ScraperWiki, about our dilemma.
As I’m sure you’re well aware the demise of ScraperWiki Classic has been a thing of great sadness for us. For us at least it hit a real sweet spot. The collaboration was great. Not having to host things was fabulous. The scraping happening whenever and the result being stored in an API accessible db was magical. Also, not having to trust that someone’s code edit will not nuke your server another bonus.
Thank you for everything!
And then on the question of what to do next.
We had a bit of panic at the end of last year when we thought it was shutting down in September and we had to move a heap of scrapers somewhere.
We had an internal scraping thing for PlanningAlerts which still has a bunch of scrapers running on it. Initially we were just going to move everything back there and figure out what to do next. It was a scary prospect having to go back to that because in the days when that was the only thing we used we never had a single scraper code contribution and that’s not pleasant when you have over 80 scrapers to maintain.
Introducing Morph
So just before Christmas I made the difficult decision to take on writing a new scraping platform. I wanted to make something which would be a replacement for ScraperWiki Classic but with a twist that puts a much greater emphasis on collaboration. I started building Morph.
![]()
It’s really exciting to be able to share this with you now!
Morph is built around GitHub. GitHub has become the de-facto way that open source software developers collaborate. They truly have nailed the solution with pull requests, their issue system, commenting on code, and social discovery through starring repositories and more.
It’s important to me to leverage those tools with Morph and integrate them very tightly so that Morph becomes a way of using Github but that’s specialised towards scrapers. I’ve made a start on that now and already we can see that it’s working.
The idea with Morph is to borrow the best of ScraperWiki Classic, merge it with the best of GitHub, and then build on top of that to really streamline the process of writing and running scrapers.
Writing and running a scraper yourself is something that any capable developer can do without Morph. With Morph it’s fun and easy.
How Does Morph Work?
A scraper on Morph is a Python, Ruby or PHP script that collects information from web pages and writes it to an SQLite database in its working directory. That’s it. What information the scraper collects, how it does that and how it writes to the database, that’s up to you.
The scraper code is kept in a repository on GitHub which is linked to the scraper on Morph.
You develop the scraper on your local machine and when you’re ready to run it you can test it on Morph with a special command line tool. When you’re happy you commit your change to git. The next time the scraper runs on Morph it picks up the latest code.
The resulting data is stored in a database that you can query through an API. Or you can just download all the data as JSON or as a CSV (you can import into a spreadsheet) or just download a whole binary SQLite database.
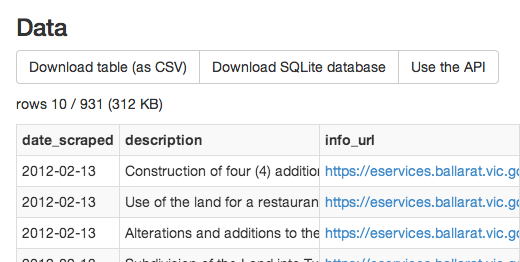
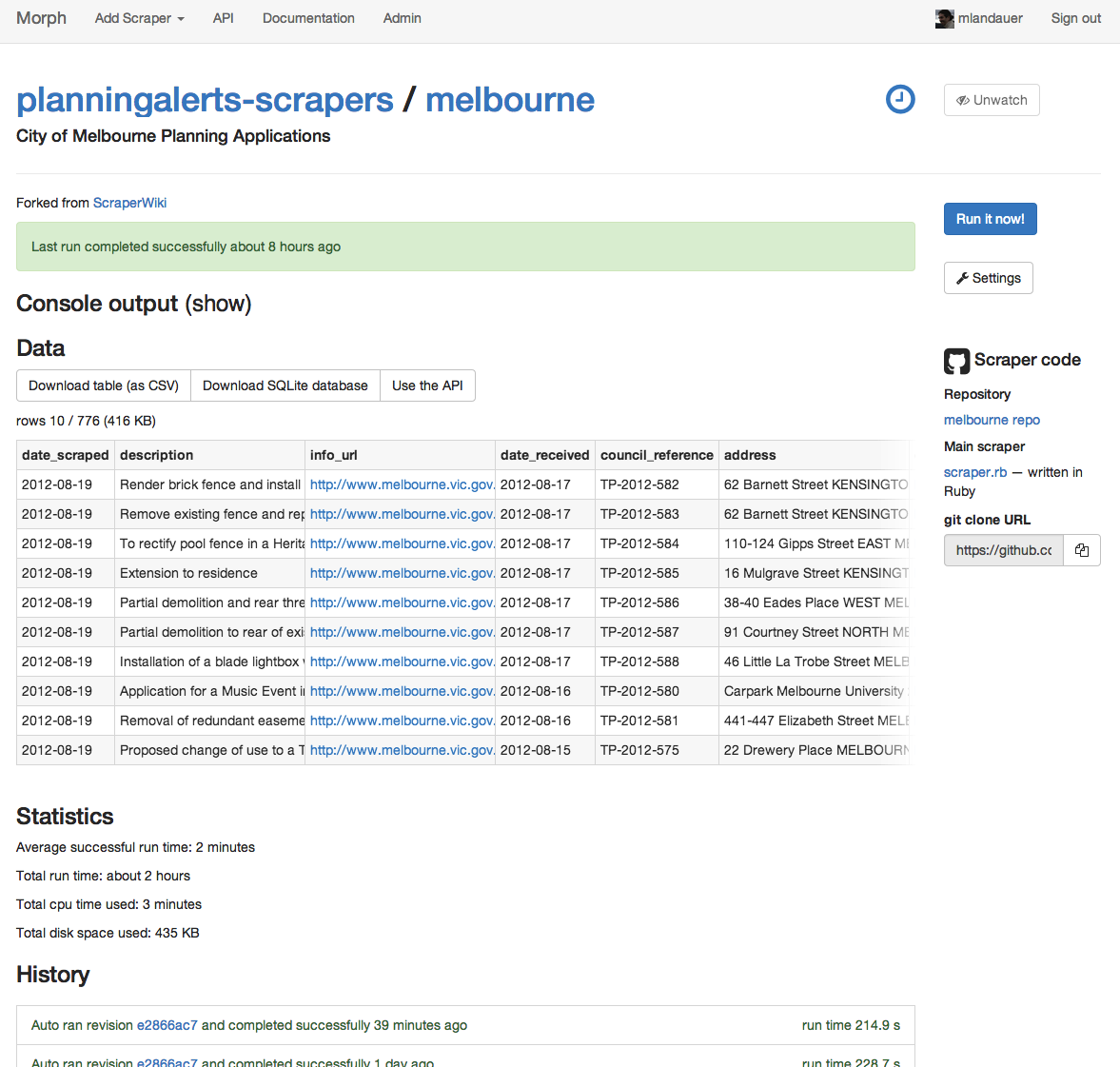
Morph will run your scrapers for you automatically if you want. It will email you if there are problems with your scrapers or someone else’s if you choose.
You get great visibility on what a scraper is doing
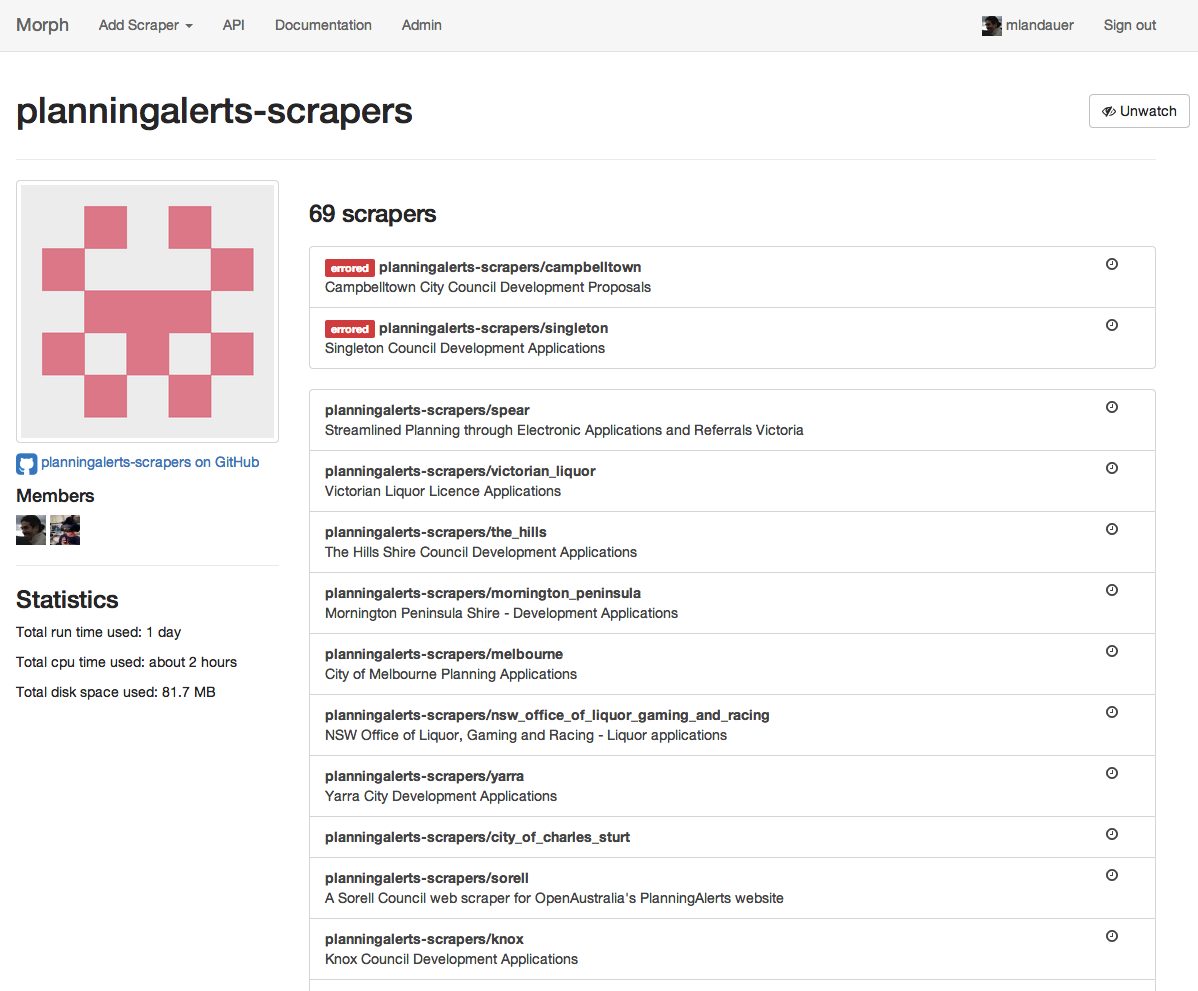
Morph supports organisations. You can group a whole set of scrapers together in an organisation which multiple people have access to.
If you’re a user of ScraperWiki Classic it couldn’t be easier to bring your scraper over to Morph.
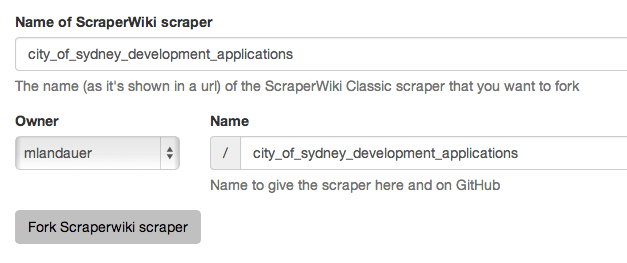
You just put in the name of your scraper on ScraperWiki Classic and if the defaults are fine you just click the fork button. The code is put on Github (automatically tweaked for a few naming changes), the data is imported into Morph and in most cases the scraper will run fine without any changes at all! When we transferred 69 PlanningAlerts scrapers from ScraperWiki to Morph only 3 or 4 scrapers needed any changes.
Morph supports scrapers written Ruby, PHP and Python with the plan to support Javascript (and anything else enough people want)
So, please go ahead start using Morph!
https://morph.io
And here’s your part of the deal. Please let us know what you think. Did it work well for you? Something that could be clearer? Let us know.
Keeping Morph going
OpenAustralia Foundation will be letting anyone run arbitrary code on our servers. This will take computing power and generate traffic. Because we’re paying for those servers and this is likely to need a lot of computing power this is not sustainable.
It is our intention to keep Morph free for most people; the casual user who has a few scrapers that are pretty lightweight. Morph should be an incredibly useful tool that they can depend on.
For the heavy users we will be bringing in paid plans that pay for continued development and the serious server infrastructure that will be needed.
If there is need for it we also intend to support private scrapers which will be under a paid plan as well.
What next for Morph?
There are of course many possibilities.
We’d like to make scraping more accessible so it doesn’t even require writing code. One approach to that would be to write a very high level scraping library that can cover 90% of situations but isn’t really like programming at all. It describes the fields, how multiple pages are navigated and it does the rest.
Then, we create a user-interface that allows you to pick fields from any website that you would like to extract. Behind the scenes it turns that into some code that uses our high level scraping library. If something more complicated needs to get done the existing generated code can be used as a starting point.
The vision there is that Morph maintains all its power and flexibility for the experienced programmer and allows a non-programmer to scrape just as well as the programmer for the common situations.
We’re particularly excited about the possibilities here for making data journalism more accessible to all journalists not just the ones that know how to program. In fact we’ve applied to the Walkley Grants for Innovation in Journalism for funding to pursue this idea.
We’d also like to continue to relentlessly pursue ease of use and design features to increase collaboration.
Enough of what we want it to do. The most important thing is what do you want for the future?
Let us know either by emailing us or even better if you put it up at https://github.com/openaustralia/morph/issues
One Trackback
[…] الويب بالأبطال المجهولين في تحرير البيانات. وقد أعلنت منظمة أستراليا المفتوحة عن منصة تجريف جديدة […]